
Abstrak
LATAR BELAKANG
Penelitian ini bertujuan untuk mengukur indikator bioavailabilitas (BA), termasuk fungsi penghalang epitel, permeabilitas nyata ( P app ) dan rasio efluks, dari 84 jenis fitokimia menggunakan sel Caco-2 dan mengembangkan sistem model prediktif menggunakan pembelajaran mesin dengan model hubungan struktur-sifat kuantitatif (QSPR) berdasarkan indikator BA dan Sistem Jalur Masuk Molekuler Sederhana Isomerik (SMILES). Analisis fitokimia dilakukan dengan metode analisis HPLC yang tervalidasi.
HASIL
Dengan indikator BA ini, Isomeric SMILES termasuk informasi seperti stereokimia, struktur kimia dan sifat fitokimia dikodekan ke deskriptor molekuler menggunakan PaDEL-Descriptor dan alvaDesc. Validitas set data diverifikasi menggunakan analisis komponen utama, plot leverage dan plot Williams. Dalam kasus resistensi listrik transepitel (TEER), R 2 Train adalah 0,86, root mean square error (RMSE) Train adalah 55,25, R 2 Test adalah 0,63 dan RMSE Test adalah 74,77, berturut-turut. Mengenai aplikasi P , model menunjukkan kinerja yang kuat pada set pelatihan dengan RMSE Train sebesar 4,54 × 10 −6 dan R 2 Train sebesar 0,95 dengan hasil set pengujian (RMSE Test = 6,23 × 10 −6 dan R 2 Test = 0,91). Untuk rasio efluks, model menjelaskan 92% varians dengan RMSE Train sebesar 0,39, R 2 Train sebesar 0,92, R 2 Test sebesar 0,85 dan RMSE Test sebesar 0,71.
KESIMPULAN
Studi saat ini menunjukkan bahwa sistem prediksi untuk ketersediaan hayati, termasuk TEER, aplikasi P , dan rasio efluks, dapat dikembangkan menggunakan model QSPR, yang dapat berkontribusi pada kemajuan dalam penemuan bahan fungsional dan obat-obatan. © 2025 Penulis. Jurnal Ilmu Pangan dan Pertanian diterbitkan oleh John Wiley & Sons Ltd atas nama Society of Chemical Industry.
PERKENALAN
Fitokimia yang berasal dari tanaman telah dikembangkan sebagai obat baru dan bahan fungsional kesehatan karena aktivitas fisiologis dan biologisnya. 1 Produk terapeutik berkembang dalam berbagai bentuk, termasuk senyawa murni, ekstrak tanaman mentah, dan ekstrak tanaman terstandarisasi, sebagai hasil dari ketersediaan fitokimia yang beragam. 2 Fitokimia yang melimpah dan beragam dibagi menjadi beragam jenis dan bentuk berdasarkan metabolisme tanaman, termasuk kelompok primer (klorofil, protein, dan gula sederhana lainnya) dan kelompok sekunder (alkaloid, terpen, dan fenolik). 1 Penelitian terkini menemukan bahwa berbagai fitokimia yang dikonsumsi sebagai senyawa makanan memberikan efek metabolik, seperti pengurangan berbagai penyakit kronis dalam tubuh manusia. 3 Misalnya, steviosida dan rebaudiosida A yang diekstrak dari Stevia rebaudiana sedang dikembangkan sebagai pemanis pengganti, dan diamati memiliki beragam aktivitas yang berpotensi mencegah kanker, penyakit kardiovaskular, dan diabetes. 4 Asam ellagic, yang banyak terkandung dalam kulit buah delima, tidak hanya memiliki efek antiperadangan dengan mengurangi berbagai penanda peradangan dan mendorong biomarker antiperadangan, tetapi juga berpotensi sebagai aktivitas antikanker dengan meningkatkan jalur protein apoptosis, mendorong sitotoksisitas sel, dan menyebabkan terhentinya siklus sel. 5 Sebuah penelitian sebelumnya menunjukkan bahwa krisazin dalam Rheum palmatum dapat menjadi agen antikanker potensial berdasarkan hasil pengurangan kematian sel apoptosis pada sel kanker lambung manusia SNU-1. 6 Meskipun penelitian ekstensif tersedia untuk mengetahui efek biologis fitokimia, penelitian tentang bioavailabilitas termasuk metabolisme fitokimia masih jarang.
Bioavailabilitas fitokimia sangat penting untuk mengidentifikasi efek bioaktif dari komponen dan menemukan agen farmasi baru. 7 Karena dosis fitokimia yang mencapai daerah target setelah pemberian oral terkait dengan kemanjuran dalam tubuh, memahami dan meningkatkan bioavailabilitas fitokimia dalam tubuh manusia merupakan faktor kunci untuk mengembangkan perawatan terapeutik yang kuat dan memajukan penelitian farmasi. 8 Bioavailabilitas fitokimia dijelaskan dalam hal penyerapan (A), distribusi (D), metabolisme (M) dan ekskresi (E) dari komponen. 9 Secara rinci, interaksi molekul bioaktif dan membran sel memainkan peran mendasar dalam penyerapan seluler, yang merupakan mekanisme penting aktivitas biologis dalam tubuh. 10 Sel Caco-2 yang berasal dari sel kolon adenokarsinoma telah digunakan sebagai model prediksi in vitro untuk memprediksi bioavailabilitas komponen bioaktif. 11 Membran epitel, yang terdiri dari sel Caco-2, dapat melindungi membran usus, mengendalikan perubahan biologis seperti peradangan, infeksi, dan metastasis kanker, serta mengubah permeabilitas penghalang sebagai respons terhadap berbagai sinyal normal dalam tubuh. 12 Model sel Caco-2 terkenal karena memberikan wawasan utama ke dalam tahap awal penemuan obat baru, khususnya mengenai senyawa bioaktif pada permeabilitas usus, transportasi, penyerapan, dan bioavailabilitas. 13 Penelitian lebih lanjut masih dilakukan sehubungan dengan pengembangan model sel Caco-2 untuk menjelaskan karakteristik matriks, kelarutan, stabilitas, dan penyerapan fitokimia dalam penggunaan obat dan makanan fungsional kesehatan. 14 Penelitian tentang permeabilitas dan bioavailabilitas fitokimia menggunakan model sel Caco-2 merupakan langkah mendasar dalam pengembangan obat baru dan bahan fungsional kesehatan. 15
Model Hubungan Struktur-Sifat Kuantitatif (QSPR) merupakan sistem pembelajaran mesin prediksi yang efektif untuk menganalisis sifat biokimia seperti bioavailabilitas.16 Model QSPR secara matematis mengungkapkan korelasi antara karakteristik struktural fitokimia, yang diukur dengan deskriptor molekuler dan sifat fisik, kimia, dan biologisnya. 17 Isomeric Simplified Molecular Input Line Entry (SMILES), termasuk informasi seperti stereokimia, struktur kimia dan sifat fitokimia, dikodekan ke 40 deskriptor molekuler, termasuk maxHBint4, maxHBint7, SpMAD_Dzs, ALogP, maxHBint5, maxHBint9, maxHBd, maxHBint3, mindssC, SHsOH, minHBint6, minHCsats, minHBint9, AATSC3c, ATSC2c, minHBint3, MATS1e, mindO, minHCsatu, VE1sign_B(s), P_VSA_LogP_4, P_VSA_LogP_5, P_VSA_e_3, Eta_D_epsiD, SpMAD_EA(dm), SpMAD_AEA(ed), Chi1_EA, Eig01_AEA(ed), CATS2D_02_AL, SHED_DL, F03[C N], F04[N N], qpmax, qnmax, ALOGP2, SAscore, LLS_01, Hypertens-80, MDEC-23 dan MDEC-33 menggunakan PaDEL-Descriptor dan alvaDesc. 18 , 19 Distribusi 40 deskriptor terpilih divisualisasikan dalam ruang kimia dengan analisis komponen utama (PCA). Domain penerapan (AD) menggunakan plot Williams dan plot leverage mengidentifikasi keandalan data indikator bioavailabilitas yang selaras dengan pedoman ketiga dalam prinsip-prinsip OECD. 20
Penelitian ini tidak hanya bertujuan untuk mengkarakterisasi indikator bioavailabilitas, termasuk resistensi listrik transepitel (TEER), permeabilitas nyata ( P app ) dan rasio efluks (ER), untuk 84 jenis fitokimia menggunakan model sel Caco-2, tetapi juga mengembangkan sistem model prediktif dengan menggunakan model QSPR yang memanfaatkan regresor hutan acak dan SMILES Isomerik dengan indikator bioavailabilitas.
BAHAN DAN METODE
Bahan kimia dan reagen
Standar analitis Atropin, hinokitiol, luteolin, punicalagin, silybin, baicalin, chrysin, griseofulvin, naringin, salisin, troxerutin, asam ellagik, asam rosmarinat, (−)-epicatechin, (+)-catechin, asam (+)-usnic, (±)-evodiamine, asam p-klorokinamat, alkohol sinamat, (S)-(+)-camptothecin, 2-(2-hidroksi etil) fenol, 2-(4-hidroksifenil) etanol, 3-(3,4-dihidroksifenil)- l -alanin, asam sinapinat, 4-formilfenil β- d -alopiranosida, 4′-hidroksi-3′-metoksiasetofenon, asam abiet, aegelin, allantoin, amigdalin, andrografolida, arbutin, betulin, baicalein, tiostrepton, berberin klorida hidrat, bergapten, bergenin, biochanin A, bisdemetoksikurkumin, brusin hidrat, kapsaisin (alami), krisazin, kurkumin (alami), kurkumin (sintetis), daidzein, dikumarol, diosgenin, diosmin, asam ellagik, dihidrat, flavokawain A, formononetinm, asam glisirizin, glisirizin, gramin, harmin, hekogenin, hematoksilin hidrat, hesperetin, hesperidin khellin, magnolol, neohesperidin dihidrokalkon, asam nordihidroguaiaretik, noskapin hidroklorida hidrat, papaverin hidroklorida, floretin, phlorizin, piceid, puerarin, purpurin, kuinidin, rebaudiosida A, resveratrol, rhododendrol, rotenon, s -alil- l -sistein, sesamol, steviosida, sinefrin, asam sinamat, asam m -kumarat, asam p -kumarat, dan β-sitosterol diperoleh dari Tokyo Chemical Industry (Tokyo, Tapan). Asam format diperoleh dari Fisher Scientific (Fair Lawn, NJ, AS). Asam fosfat dan amonium asetat dibeli dari Sigma Aldrich Co. (St Louis, MO, AS). Metanol, air, dan asetonitril (ACN) bermutu HPLC disediakan oleh JT Baker (Phillipsburg, NJ, AS). Media Dulbecco’s Modified Eagle (DMEM) dengan fenol merah, serum sapi janin (FBS), Dulbecco’s phosphate-buffered saline (DPBS), dan penisilin-streptomisin (P/S) dibeli dari Biowest (Riverside, MO, AS).
Analisis HPLC-UV
Untuk mengidentifikasi dan mengukur asam sinamat dan turunannya dari media kultur sel Caco-2, kromatografi cair kinerja tinggi (HPLC) dengan detektor ultraviolet (UV) (Nanospace SI-2, Osaka SODA co., LTD, Osaka, JAP) dilakukan. Sistem tersebut digunakan dengan kolom fase terbalik YMC-PACK ODS-A (150 × 4 mm, 5,0 μm, YMC, Kyoto, Jepang). Sejumlah kecil sampel standar (20 mg) dilarutkan dalam 2 mL 1 L/L −1 EtOH dan air suling. Fase gerak terdiri dari air yang mengandung 0,5 mL/L −1 asam format dan ACN yang mengandung 0,5 mL L −1 asam format. Suhu kolom dipertahankan pada 37 °C. Polifenol lainnya diidentifikasi dan diukur menggunakan Nanospace SI-2 (Shiseido, Tokyo, Jepang) dengan detektor UV dan kolom CAPCELL PAK MG II C18 (5 μm, 150 × 4,6 mm) (Osaka Soda, Osaka, Jepang). Fase mobil terdiri dari 0,5 mL L −1 asam format dalam air suling dan 0,5 mL L −1 asam format dalam ACN. Suhu kolom dipertahankan pada 37 °C. Dalam kasus fitokimia lainnya, HPLC-UV dilakukan seperti yang dijelaskan dalam Informasi pendukung (Tabel S1 ).
Validasi metode bioanalitik menggunakan HPLC-UV
Metode analisis HPLC-UV terhadap 84 jenis fitokimia divalidasi untuk linearitas, akurasi, presisi dan sensitivitas, yang mencakup batas deteksi (LOD) dan batas kuantifikasi (LOQ). Linearitas ditentukan dari tiga analisis replikasi pada empat rentang konsentrasi, dari 1 hingga 50 μg mL −1 . Koefisien korelasi ( r 2 ) dihitung menggunakan persamaan regresi di Excel 365 (Microsoft Corp., Redmond, WA, AS). Akurasi ditentukan oleh tingkat kesesuaian antara konsentrasi terukur dan konsentrasi nominal. Akurasi (%) dihitung menggunakan:
![]()
Presisi dinyatakan sebagai pengulangan, yaitu estimasi hasil yang diperoleh oleh operator yang sama, menggunakan sistem pengukuran, kondisi, dan laboratorium yang sama dalam waktu singkat. Pengulangan metode analisis dihitung berdasarkan persentase deviasi standar relatif (%RSD):
![]()
Sensitivitas dievaluasi berdasarkan batas deteksi dan kuantifikasi (LOD dan LOQ) dengan kurva kalibrasi:

di mana σ merupakan SD dari intersep y kurva regresi dan S merupakan kemiringan kurva kalibrasi.
Penambangan data
Indikator bioavailabilitas, seperti ΔTEER (Ω cm −2 ), P app dan ER oleh sel Caco-2, dinilai seperti yang dijelaskan di bawah ini. Sel kanker usus besar manusia Caco-2 diperoleh dari Korean Cell Line Bank (KCLB, Seoul, Korea) dan kultur stok dipertahankan dalam DMEM yang dilengkapi dengan 100 mL L −1 FBS dan 10 mL L −1 P/S. Sel disemai dalam pelat kultur 12-transwell (Corning Inc., Corning, NY, AS) pada kepadatan 1 × 105 sel per sumur dan diinkubasi pada 37 °C dalam 50 mL L −1 CO 2 , dan media pertumbuhan diganti setiap 2–3 hari. Sel dari nomor lintasan 52 hingga 65 digunakan untuk percobaan.
Lapisan tunggal Caco-2 dengan nilai TEER awal lebih dari 300 Ω cm −2 digunakan untuk memastikan integritas sel epitel, dan pengukuran TEER dilakukan menggunakan sistem Millicell ERS-2 (Millipore, Bedford, MA, AS). Nilai TEER diukur pada menit ke-0 dan ke-120 dan dinyatakan sebagai: ΔTEER (Ω cm −2 ) = nilai TEER (Ω cm −2 , pada menit ke-120) − nilai TEER (Ω cm −2 , pada menit ke-0). Setelah menghilangkan media kultur, transwell dicuci dengan DPBS. Eksperimen transpor dilakukan dengan menambahkan larutan standar encer dari setiap fitokimia (100 μg mL −1 ) ke sisi apikal (AP, 500 μL) atau sisi basal (BL, 1500 μL) untuk menilai permeabilitas dua arah. Setelah inkubasi selama 2 jam, 500 μL media kultur dikeluarkan dari kedua sisi dan didinginkan pada suhu 4 °C sebelum melakukan analisis HPLC. P app dan ER dihitung menggunakan:

Nilai efluks yang lebih besar dari 2 menunjukkan bahwa senyawa tersebut mungkin mengalami efluks aktif. Semua indikator bioavailabilitas dari 84 fitokimia digandakan tiga kali, yang terdiri dari 255 set data.
Pemrosesan pemilihan fitur dan kumpulan data
Dataset tersebut terdiri dari SMILES Isomerik dan indikator bioavailabilitas untuk 84 fitokimia. Seperti yang ditunjukkan dalam Informasi pendukung (Tabel S2 ), SMILES isomerik diperoleh dari basis data daring. 21 Eliminasi Fitur Rekursif (RFE) mengidentifikasi deskriptor molekuler terpilih yang paling penting untuk pemilihan fitur berdasarkan kesalahan akar kuadrat rata-rata (RMSE) sesuai dengan penelitian sebelumnya. 18 Secara khusus, algoritma genetika (GA) diterapkan untuk menyempurnakan pemilihan, mengembangkan solusi selama 100 generasi, dan akhirnya mengidentifikasi subset akhir dari deskriptor yang dioptimalkan. 18 SMILES isomerik diubah menjadi deskriptor molekuler, termasuk maxHBint4, maxHBint7, SpMAD_Dzs, ALogP, maxHBint5, maxHBint9, maxHBd, maxHBint3, mindssC, SHsOH, minHBint6, minHCsats, minHBint9, AATSC3c, ATSC2c, minHBint3, MATS1e, mindO, minHCsatu, VE1sign_B(s), P_VSA_LogP_4, P_VSA_LogP_5, P_VSA_e_3, Eta_D_epsiD, SpMAD_EA(dm), SpMAD_AEA(ed), Chi1_EA, Eig01_AEA(ed), CATS2D_02_AL, SHED_DL, F03[C N], F04[N N], qpmax, qnmax, ALOGP2, SAscore, LLS_01, Hypertens-80, MDEC-23 dan MDEC-33 menggunakan PaDEL-Descriptor dan alvaDesc. Untuk memastikan keandalan pemrosesan data, nilai NaN dari indikator bioavailabilitas dalam dataset tersebut dihilangkan atau diimputasikan menggunakan nilai rata-rata dari masing-masing indikator yang dihitung di seluruh dataset. Dataset tersebut dibagi menjadi variabel penjelas ( X ) dan variabel target ( Y ). Deskriptor molekuler yang dihitung digunakan sebagai variabel penjelas, dan indikator bioavailabilitas termasuk ΔTEER (Ω cm −2 ), P app dan ER digunakan sebagai variabel target. Dataset tersebut dibagi menjadi set pelatihan dan pengujian menggunakan rasio split 80–20. Untuk menstandardisasi rentang variabel penjelas, data dinormalisasi menggunakan fungsi StandardScaler dari pustaka scikit-learn (Python v3.11.5). Data pelatihan digunakan untuk menyesuaikan skala, dan set pelatihan dan pengujian ditransformasikan sebagaimana mestinya. Selain itu, PCA dilakukan untuk memvisualisasikan distribusi 40 deskriptor terpilih dalam ruang kimia.
Pemodelan hubungan struktur-properti kuantitatif
Model QSPR digunakan untuk memprediksi indikator bioavailabilitas berdasarkan deskriptor molekuler yang diekstrak dari Isomeric SMILES menggunakan model regresor hutan acak, yang dilatih menggunakan data pelatihan berskala dengan 100 pohon keputusan (estimator) dan benih acak 42 untuk memastikan reproduktifitas hasil. Kinerja model QSPR yang dilatih dievaluasi menggunakan set pelatihan dan set uji. RMSE dari set pelatihan (RMSE Train ), R -kuadrat dari set pelatihan ( R 2 Train ), RMSE dari set uji (RMSE Test ) dan R -kuadrat dari set uji ( R 2 test ) digunakan untuk mengevaluasi akurasi dan ketahanan model dalam memprediksi indikator bioavailabilitas.
Evaluasi model
Validasi silang lima kali lipat dilakukan untuk mengevaluasi kinerja prediktif model. Kumpulan data dipartisi menjadi lima subset yang sama, dan model dilatih dan divalidasi lima kali. Dalam setiap iterasi, empat subset digunakan untuk pelatihan, sedangkan subset yang tersisa berfungsi sebagai set validasi. Prosedur ini diulang hingga setiap subset telah digunakan satu kali sebagai set validasi. Untuk memastikan ketahanan evaluasi, pengocokan data dilakukan sebelum pemisahan, dan benih acak tetap (42) digunakan untuk menjaga konsistensi di seluruh eksperimen. RMSE dari validasi silang (RMSE CV ) dihitung untuk setiap lipatan, dan nilai rata-rata di semua lipatan dihitung untuk meringkas kinerja model. Selain itu, koefisien determinasi validasi silang ( R 2 CV ) dihitung untuk setiap lipatan, dengan nilai rata-rata R 2 dilaporkan untuk menilai kecocokan model secara keseluruhan. Selanjutnya, setelah menyelesaikan validasi silang lima kali lipat, nilai prediksi dan eksperimen dari setiap set validasi lipatan digabungkan. Diagram sebar dibuat untuk memvisualisasikan hubungan antara nilai prediksi dan nilai aktual di seluruh set pengujian dari validasi silang lima kali lipat.
Domain penerapan
AD dari model QSPR dinilai melalui penggunaan nilai leverage dan residual terstandarisasi sesuai dengan pedoman OECD. 20 Nilai leverage digunakan untuk mengevaluasi apakah suatu senyawa berada dalam AD model. Nilai-nilai ini diperoleh dari elemen diagonal matriks topi ( H ), yang dihitung menggunakan:
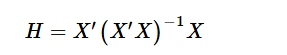
di mana X merupakan matriks deskriptor molekuler dalam set pelatihan, dengan n baris (senyawa) dan p kolom (deskriptor), X’ merupakan transpos matriks X , dan ( X’X ) −1 merupakan kebalikan dari produk X’X . Leverage peringatan ( h *) dihitung untuk menentukan ambang batas yang di luarnya prediksi model dianggap tidak dapat diandalkan. Ambang batas ini diberikan oleh:
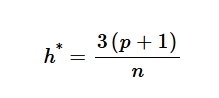
di mana p adalah jumlah deskriptor molekuler dan n adalah jumlah senyawa pelatihan. Senyawa dengan nilai leverage yang melebihi h * dianggap berada di luar AD model.
Selain itu, residual terstandar dihitung dengan membagi residual data pelatihan dengan simpangan bakunya. AD kemudian dinilai secara visual melalui plot Williams, di mana nilai leverage diplot terhadap residual terstandar. Senyawa dengan residual terstandar lebih besar dari ±3 ditandai sebagai outlier potensial, yang menunjukkan bahwa prediksi untuk senyawa ini mungkin tidak dapat diandalkan.
Untuk set pengujian atau senyawa baru, nilai leverage ( h ) dihitung menggunakan:
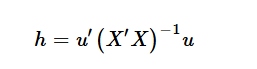
di mana u adalah matriks deskriptor molekuler untuk senyawa baru dan u′ adalah transposnya. Persamaan ini memungkinkan penghitungan nilai leverage untuk senyawa di luar set pelatihan, yang menentukan apakah senyawa tersebut termasuk dalam AD model.
HASIL DAN PEMBAHASAN
Validasi metode bioanalisis berbagai fitokimia
Validasi metode bioanalisis dari 84 fitokimia dilakukan dengan pedoman Kementerian Keamanan Pangan dan Obat (MFDS). 22 Berbagai metode analisis menggunakan HPLC-UV untuk fitokimia ini termasuk 20 polifenol dan delapan asam sinamat dengan turunannya yang diperoleh dari penelitian kami sebelumnya divalidasi berdasarkan persamaan regresi ( R 2 , x -variabel: konsentrasi fitokimia, y -variabel: intensitas sinyal HPLC-UV), akurasi, presisi, LOD dan LOQ (Tabel 1 ). Secara keseluruhan, metode yang digunakan untuk 84 fitokimia menunjukkan linearitas yang hebat, dengan nilai lebih dari 0,9812 dari R 2 dalam rentang konsentrasi 1–100 μg mL −1 . Nilai R 2 untuk asam ellagic dihidrat dan magnolol masing-masing adalah 0,9812 dan 0,9814, yang merupakan yang terendah di antara semua fitokimia. Rentang akurasi untuk 84 fitokimia adalah 72,14–126,67%. Namun, luteolin 1 μg mL −1 , naringin 5 μg mL −1, dan asam sinapinat 5 μg mL −1 melampaui rentang ini. Presisi berkisar dari 0,038% hingga 16,80%. Nilai LOD dan LOQ minimum ditemukan dari 0,004 dan 0,01 μg mL −1 untuk naringin, masing-masing, dan nilai LOD dan LOQ maksimum adalah 3,55 dan 10,76 μg mL −1 untuk rebaudioside A, masing-masing. Oleh karena itu, metode bioanalisis yang dikembangkan dalam penelitian ini dilakukan sesuai dengan pedoman MFDS dan terbukti efektif diterapkan untuk penentuan berbagai fitokimia dalam media sel Caco-2.
| Fitokimia | Sinar UV (nm) | RT (menit) | Kisaran konsentrasi (μg mL −1 ) | Persamaan regresi ( R 2 ) | Akurasi (%) | Presisi (%) | LOD (μg ml -1 ) | Kualitas air (μg mL −1 ) |
|---|---|---|---|---|---|---|---|---|
| Atropin | 254 | 3.1 | 1–50 | kamu = 4831,5 x – 2092,7 (0,9994) | 96,21–100,71 | 0,038–9,03 | 1.83 | 5.57 |
| Hinokitiol | 270 | 3.18 | 10–100 | kamu = 43151 x – 206469 (0,9927) | 78,06–103,84 | 1.16–13.20 | 3.55 | 10.76 |
| Punicalagin | 254 | 5.5 | 5–10 | ynya = 12404x + 855,73 (0,9999) | 93,85–104,35 | 1,96–5,50 | 0.23 | 0.71 |
| Obat Griseofulvin | 280 | 19.2 | 1–50 | kamu = 37724 x – 8061,2 (0,9993) | 112,96–123,06 | 0,05–0,29 | 0,04 | 0.13 |
| Salisilat | 200 | 10.6 | 1–50 | ynya = 71318x + 23 736 (0,9993) | 99,23–104,76 | 4.45–8.01 | 0.68 | 2.07 |
| Asam ellagic | 360 | 3.1 | 5–50 | kamu = 129476 x – 108739 (0,9989) | 90,26–100,91 | 5.31–6.99 | 2.35 | 7.14 |
| (+) Asam usnat | 380 | 31.5 | 1–50 | kamu = 43157 x – 2153,2 (1,0000) | 100,14–123,93 | 0,18–2,03 | 0.10 | 0.31 |
| (±)-Evodiamin | 280 | 22 | 1–50 | kamu = 27508 x – 8822,6 (0,9996) | 95,26–122,91 | 0,06–0,76 | 0,02 | 0,07 |
| ( S )- (+)- Kampotesin | 360 | 13.2 | 1–50 | ynya = 70252x + 23239 (0,9995) | 99.08–103.12 | 0,29–0,60 | 0,05 | 0.17 |
| 2-(2-Hidroksietil) fenol | 200 | 8.4 | 5–10 | kamu = 129943 x + 94.001 (0,9988) | 96,45–111,54 | 0,30–2,22 | 0.20 | 0.61 |
| 2-(4-Hidroksifenil) etanol | 280 | 6.1 | 5–50 | kamu = 8852,4 x + 3908,1 (0,9986) | 86,09–105,57 | 0,10–0,74 | 0,02 | 0,06 |
| 3-(3,4-Dihidroksifenil) -l- alanin | 282 | 3.96 | 5–50 | kamu = 64228 x – 9950,2 (0,9999) | 98,33–102,02 | 0,13–2,33 | 2.35 | 7.14 |
| 4-Formilfenil β- d -alopiranosida | 280 | 3.6 | 5–50 | kamu = 41541 x – 39.695 (0,9976) | 92.16–101.24 | 0,27–3,93 | 0.23 | 0,70 |
| 4′-Hidroksi-3′-metoksiasetofenon | 280 | 9.5 | 1–50 | ynya = 53392x + 8669,3 (0,9999) | 89,23–101,65 | 0,08–0,49 | 0,07 | 0.21 |
| Asam abietat | 254 | Tanggal 35.05 | 5–50 | ynya = 18535–941,35 (0,9998) | 97,33–104,62 | 0,08–0,39 | 0,05 | 0.17 |
| Alantoin adalah zat kimia yang dapat bereaksi cepat terhadap rangsangan saraf. | 190 | 2.1 | 5–50 | kamu = 9769,5 x – 7220,6 (0,9994) | 92,07–100,39 | 0,21–0,78 | 0.21 | 0.66 |
| Amigdalin | 210 | 2.3 | 1–50 | kamu = 4581,1 x + 2944,5 (0,9996) | 99,74–101,17 | 1.56–3.46 | 0.76 | 2.31 |
| Andrografolida | 254 | 13.8 | 5–50 | kamu = 124,47 x + 148,97 (0,9982) | 99,34–110,71 | 2.26–8.85 | 1.35 | 4.11 |
| Arbutin | 190 | 3.3 | 5–50 | ynya = 12707x + 22 426 (0,9909) | 79,95–113,49 | 0,78–3,91 | 1.30 | 3.96 |
| Betulin | 210 | 14.2 | 5–50 | kamu = 9753,4 x − 70,669 (0,9998) | 100,39–122,63 | 4.58–6.56 | 0.52 | 1.58 |
| Tiostrepton | 254 | 22.4 | 5–50 | kamu = 21346 x − 653,88 (0,9999) | 97,75–100,91 | 0,18–0,41 | 0,04 | 0.14 |
| Berberin klorida hidrat | 254 | 12.8 | 5–50 | kamu = 47898 x – 22383 (0,9995) | 96,75–103,32 | 0,30–1,57 | 0.43 | 1.33 |
| Bergapten | 254 | 19.1 | 5–50 | ynya = 20859x + 3896 (1.0000) | 99,86–101,75 | 0,22–0,40 | 0,25 | 0,75 |
| Bergen | 254 | 2.6 | 5–50 | kamu = 17.088 x – 9963,3 (0,9994) | 95,96–100,58 | 0,52–5,95 | 0.74 | 2.24 |
| Bisdemetoksikurkumin | 420 | 20.8 | 1–50 | kamu = 151318 x – 27892 (0,9999) | 98,19–109,78 | 0,31–0,68 | 0,08 | 0.26 |
| Brucine hidrat | 254 | 2.6 | 5–50 | kamu = 18934 x – 44941 (0,9940) | 83.02–101.34 | 0,46–1,08 | 0.18 | 0.57 |
| Kapsaisin (alami) | 280 | 22.8 | 5–50 | ynya = 3545x – 8178 (0,9929) | 81,31–101,80 | 0,19–1,39 | 0.17 | 0.54 |
| Krisazin | 254 | 3.6 | 5–50 | kamu = 24718 x – 11 487 (0,9996) | 96,36–100,59 | 0,16–2,19 | 0.16 | 0.51 |
| Kurkumin (alami) | 420 | 21.8 | 1–50 | kamu = 102626 x – 18398 (0,9998) | 97,86–111,02 | 0,07–0,11 | 0,02 | 0,07 |
| Kurkumin (sintetis) | 254 | 22.9 | 5–50 | ynya = 25887x + 4504,5 (0,9999) | 82.10–102.56 | 0,16–3,24 | 0.18 | 0.56 |
| Diosgenin | 194 | 16.1 | 5–50 | ynya = 11729x + 18 349 (0,9960) | 98,44–108,78 | 0,60–10,51 | 1.04 | 3.18 |
| Asam ellagic dihidrat | 254 | 1.97 | 5–50 | ynya = 6626x + 27742 (0,9812) | 97,76–108,48 | 0,34–16,80 | Jam 3.30 | Jam 10.00 |
| Asam glisiretik | 254 | 29.5 | 1–50 | kamu = 20794 x – 1627,8 (1,0000) | 99,04–100,03 | 0,10–1,18 | 0,08 | 0.26 |
| Glisirizin | 254 | 17.6 | 5–50 | kamu = 9018,8 x − 11 466 (0,9970) | 92.17–101.41 | 0,61–1,51 | 0.23 | 0.71 |
| Biji Gramin | 210 | 4.3 | 5–50 | kamu = 130734x + 150.068 (0,9969) | 98,02–108,71 | 0,54–2,49 | 2.01 | 6.09 |
| Harmin | 254 | 8.5 | 5–50 | kamu = 102398 x – 104942 (0,9980) | 92,84–104,80 | 0,41–10,25 | 2.89 | 8.78 |
| Hekogenin | 194 | 6.7 | 5–50 | kamu = 2043,7 x + 74,016 (0,9994) | 96,54–106,80 | 1.91–21.20 | 0.84 | 2.56 |
| Hematoksilin hidrat | 380 | 2.7 | 1–50 | kamu = 6799,9 x – 13959 (0,9911) | 72.14–99.31 | 0,57–5,63 | 0.76 | Jam 2.30 |
| Obat Hesperidin | 210 | 10.5 | 5–50 | kamu = 16267 x – 3260,4 (0,9909) | 83,29–121,81 | 4.09–8.87 | 0,89 | 2.71 |
| Khellin | 254 | 14.4 | 5–50 | kamu = 99560 x – 16909 (1,0000) | 98,08–100,21 | 0,11–0,38 | 0,05 | 0.16 |
| Magnol | 280 | 26.6 | 5–50 | kamu = 10015 x – 37951 (0,9814) | 89,60–102,90 | 0,001–0,11 | 0.00 | 0,02 |
| Asam Nordihidroguaiaretik | 200 | 17.7 | 1–50 | kamu = 143788 x + 123737 (0,9921) | 87,55–104,93 | 6.59–18.18 | 2.31 | Jam 7.00 |
| Noskapin hidroklorida hidrat | 254 | 7.9 | 1–50 | ynya = 64667x + 12503 (0,9998) | 86.11–102.17 | 0,03–2,44 | 0.39 | 1.18 |
| Papaverin Hidroklorida | 254 | 8.5 | 1–50 | kamu = 74260 x – 34850 (0,9995) | 93,99–126,67 | 5.05–22.68 | 2.39 | 7.26 |
| Piceid | 320 | 8.9 | 5–50 | kamu = 32159 x – 15620 (0,9981) | 84,64–110,17 | 4.82–20.34 | 2.31 | 7.01 |
| Purpurin | 254 | 19.8 | 5–50 | kamu = 56476 x + 110 216 (0,9911) | 82,66–103,16 | 0,03–0,99 | 0,04 | 0.14 |
| Kuinidin | 254 | 2.6 | 5–50 | kamu = 33271 x – 30062 (0,9991) | 93,26–100,53 | 0,84–3,62 | 1.24 | 3.77 |
| Rebaudiosida A | 210 | 5.0 | 1–50 | kamu = 2205 x – 957,25 (0,9991) | 95,06–100,83 | 0,68–4,52 | 3.55 | 10.76 |
| Obat Resveratrol | 320 | 12.1 | 5–50 | kamu = 101213 x + 8963,2 (1,0000) | 99,44–101,59 | 0,06–0,12 | 0,03 | 0,09 |
| Rhododendrol | 200 | 9.9 | 5–50 | ynya = 90654x + 91 083 (0,9984) | 98,98–105,44 | 0,34–10,13 | 0,77 | 2.34 |
| Rotenon | 200 | 23 | 5–50 | ynya = 92169x + 13160 (0,9999) | 98,07–102,63 | 0,24–1,36 | 0.10 | 0.30 |
| S-Alil- l -sistein | 210 | 8.4 | 5–50 | kamu = 62434 x – 20174 (0,9997) | 97,06–103,01 | 0,19–4,95 | 0.26 | 0.81 |
| Sesamol | 298 | 10.1 | 1–50 | ynya = 27276x + 4381,8 (0,9999) | 95,62–101,20 | 0,84–4,14 | 0.36 | 1.12 |
| Steviosida | 210 | 5.5 | 1–50 | kamu = 1934,4 x – 167,48 (0,9997) | 96,74–116,50 | 0,51–8,91 | 0.23 | 0.71 |
| Sinefrin | 280 | 2.4 | 5–50 | ynya = 27424x + 7625,6 (0,9998) | 99,67–101,79 | 0,12–0,72 | 0.16 | 0,50 |
| beta-sitosterol | 208 | 5 | 5–50 | kamu = 266001 x + 371 262 (0,9909) | 83,34–116,02 | 0,21–2,34 | 0,65 | 1.98 |
| Lutein | 254 | 13.6 | 1–50 | kamu = 48036x – 36.409 (0,9983) | 93,5–144,7 | 0,14–1,80 | 0.34 | 1.03 |
| Baicalin | 254 | 12.5 | 10–70 | kamu = 17.711 x – 21962 (0,9987) | 83,3–101,8 | 0,18–2,63 | 0.34 | 1.03 |
| Silibin | 280 | 15.3 | 1–50 | ynya = 30766x + 2241,8 (1.0000) | 93,83–125,26 | 0,288–0,72 | 0,05 | 0.16 |
| Neohesperidin dihidrokalkon | 200 | 11.7 | 5–50 | kamu = 55356 x – 94 202 (0,9957) | 90,47–101,61 | 0,99–26,50 | 2.20 | 6.67 |
| Krisin | 254 | 20.1 | 1–50 | ynya = 54113x + 12 952 (0,9992) | 75,6–105,3 | 0,21–1,52 | 0,04 | 0.14 |
| Hesperides (bahasa Inggris: Hesperides) adalah bahasa Yunani yang berarti “berisi suara”. | 254 | 14.1 | 1–50 | ynya = 45842x + 25853 (0,9993) | 73,5–105,5 | 0,29–3,52 | 0.46 | 1.39 |
| Bahasa Naringin | 210 | 10.2 | 1–50 | kamu = 33909 x – 44290 (0,9964) | 84,3–157,9 | 0,09–0,36 | 0,004 tahun | 0,01 |
| Obat Troxerutin | 254 | 9.1 | 5–50 | y = 781x – 626,69 (0,9975) | 91,6–106,7 | 6,99–20,6 | 1.35 | 4.10 |
| (−)-Epikatekin | 280 | 6.9 | 5–50 | kamu = 8581,5 x – 3539,9 (0,9998) | 96,8–100,1 | 0,27–0,87 | 0.16 | 0.51 |
| (+)-Katekin | 280 | 6.4 | 1–50 | kamu = 9345,6 x – 2099,5 (0,9999) | 75,6–101,2 | 0,34–11,9 | 0,45 | 1.36 |
| Baicalein | 280 | 26.8 | 1–50 | kamu = 43870 x – 46818 (0,9947) | 74,7–124,4 | 0,05–0,80 | 0,05 | 0,15 |
| Biokanin A | 254 | 24.1 | 1–50 | kamu = 31611 x – 6944,1 (0,9999) | 96,3–114,5 | 0,04–0,55 | 0,02 | 0,07 |
| Daidzein | 254 | 15.2 | 1–50 | kamu = 34581 x – 5702,8 (0,9998) | 94,9–107,8 | 0,08–2,96 | 0,05 | 0.18 |
| Dikumarol | 306 | 1.3 | 5–50 | kamu = 5600,3 x + 2690,3 (0,9988) | 93,6–109,2 | 4.70–16.5 | 1.37 | 4.15 |
| Diosmin | 254 | 10.7 | 5–50 | kamu = 492,6 x – 562,32 (0,9962) | 81,1–108,8 | 1,96–3,72 | 0.84 | 2.54 |
| Flavokawain A | 360 | 26.2 | 5–50 | ynya = 93493x + 45166 (0,9984) | 88,4–106,2 | 0,20–0,54 | 0,02 | 0,06 |
| Formononetin | 254 | 15.2 | 1–50 | kamu = 33255 x – 11 037 (0,9993) | 95,3–121,3 | 0,02–1,38 | 0,02 | 0,06 |
| Floretin | 210 | 14.7 | 5–50 | ynya = 31678x + 48 305 (0,9960) | 92,7–114,3 | 7.17–20.4 | 2.67 | 8.11 |
| florizin | 210 | 10.8 | 5–50 | ynya = 17374x + 8281 (0,9936) | 90,4–124,7 | 5.32–23.0 | 3.34 | 10.1 |
| pueraria | 254 | 7.8 | 1–50 | ynya = 5154x + 353,32 (0,9992) | 93,5–104,9 | 3,90–18,5 | 0,77 | 2.35 |
| Asam rosmarinat | 320 | 10.9 | 1–50 | kamu = 21440 x − 16520 (0,9994) | 95,0–103,7 | 0,1–1,3 | 0.19 | 0,59 |
| p -asam klorosinamat | 280 | 18.3 | 1–50 | kamu = 719,47 x – 2322,6 (0,9904) | 84,1–102,05 | 0,1–1,2 | 0.37 | 1.14 |
| Alkohol sinamat | 254 | 14.5 | 1–50 | kamu = 4166 x – 153,55 (1,0000) | 99,5–100,3 | 0,02–1,6 | 0,05 | 0.17 |
| Asam sinapinat | 320 | 9.8 | 1–50 | kamu = 6489,8 x – 4429,6 (0,9997) | 99,6–144,7 | 0,07–1,8 | 0.12 | 0.36 |
| Garis pantai Aegean | 280 | 16.8 | 5–50 | kamu = 36042 x – 2895,5 (0,9999) | 88,8–101,3 | 0,03–0,2 | 0,03 | 0.10 |
| Asam sinamat | 280 | 15.1 | 1–50 | y = 56292x – 10244 (1.000) | 99,4–109,9 | 0,08–0,4 | 0,07 | 0.21 |
| M -asam kumarat | 280 | 10.5 | 1–50 | y = 94314x – 27457 (1.000) | 99,6–104,1 | 0,1–17,8 | 0.32 | 0,97 |
| p -asam kumarat | 320 | 9.4 | 1–50 | kamu = 52041 x – 5871,8 (1.000) | 99,4–107,1 | 0,1–0,4 | 0,07 | 0.21 |
Pengaruh fitokimia terhadap integritas sel epitel dari sel Caco-2
Integritas sel epitel dari sel Caco-2 diukur dengan TEER selama 120 menit inkubasi (Gbr. 1 ). Nilai variasinya (ΔTEER) untuk 84 jenis fitokimia cenderung positif, yang menunjukkan asam ellagic, betulin, neohesperidin dihydrochalcone, disomin dan dicoumarol meningkatkan nilai TEER lebih dari 100 Ω cm −2 . Sementara itu, hecogenin, capsaicin (alami), allantoin, curcumin (sintetis), arbutin, asam ellagic dihidrat, asam abietic, asam glycyrrhetic, curcumin (alami), brucine hydrate, papaverine hydrochloride, amygdalin, chrysin dan harmine tampaknya menurunkan nilai TEER kurang dari −100 Ω cm −2 . Nilai ΔTEER sangat rendah pada khellin, rhododendrol, (+)-catechin, troxerutin, sesamol, quinidine, asam sinamat dan resveratrol, berkisar antara −10 hingga 10 Ω cm −2 .

Pengukuran TEER, yang mengonfirmasi integritas barier sel epitel, merupakan aspek penting saat mengevaluasi bioavailabilitas fitokimia dan obat-obatan. 23 Penelitian sebelumnya menemukan bahwa fungsi barier usus dapat secara signifikan dikompromikan atau diperkuat oleh ko-inkubasi dengan ekstrak tanaman atau fitokimia, sedangkan penelitian lain menunjukkan bahwa beberapa fitokimia, seperti kumarin yang dikombinasikan dengan yang lain, dapat secara negatif mempengaruhi barier epitel usus dengan menghasilkan metabolit toksik. 24 , 25 Perubahan dalam TEER mengidentifikasi permeabilitas jalur paraselullar dan transelular, karena TEER sesuai dengan kekencangan sambungan ketat antarselullar. 26 Seperti halnya temuan kami, upaya sebelumnya untuk mengukur TEER untuk memperkirakan bioavailabilitas berbagai fitokimia telah dilaporkan. 23 , 27 Misalnya, biochanin A dan daidzein meningkatkan nilai TEER dari lapisan sel Caco-2 hingga 36% dan 14%, sedangkan formononetin tidak berubah secara signifikan. 27 Dalam penelitian saat ini, data TEER selanjutnya digunakan sebagai kumpulan data pelatihan untuk memprediksi ketersediaan hayati berbagai fitokimia.
Pengangkutan fitokimia melintasi lapisan usus tunggal
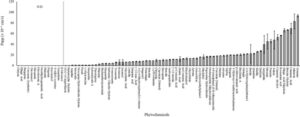
Aplikasi P untuk 84 fitokimia mengungkapkan laju transpor melintasi sel Caco-2 dari apikal ke basolateral (AP-BL) (Gbr. 2 ). Telah dijelaskan sebelumnya bahwa derajat penyerapan in vivo dapat diprediksi menurut nilai aplikasi P sebagai berikut: Aplikasi P ≤ 1 × 10 −6 cm s −1 , 1 × 10 −6 cm s −1 ≤ Aplikasi P ≤ 10 × 10 −6 cm s −1 dan Aplikasi P > 10 × 10 −6 cm s −1 masing-masing menunjukkan laju penyerapan rendah (0–20%), laju penyerapan sedang (20–70%) dan laju penyerapan tinggi (70–100%). Nilai P app dari ( S )-(+)-camptothecin, hematoxylin hydrate, aegeline dan stevioside berturut-turut adalah 0,102 , 0,303, 0,918 dan 0,979 × 10 −6 cm s −1 , menunjukkan bahwa mereka termasuk dalam kelompok dengan tingkat penyerapan rendah. Pada golongan dengan laju penyerapan sedang, noskapin hidroklorida hidrat, piceid, (−)-epicatechin, hesperidin, rebaudioside A, rotenon, tiostrepton, phlorizin, bisdemetoksikurkumin, hesperetin, berberin klorida hidrat, formononetin, troxerutin, seasamol, asam glikretik, luteolin, asam sinapinat, (+)-asam usnat, 3-(3,4-dihidroksipenil)- l -alanin, magnolol, punicalagin, (±)-evodiamin, dan krisazin disertakan dengan rentang nilai 1,06–9,96 × 10 −6 cm s −1 . Empat puluh dua fitokimia termasuk dalam kelompok dengan tingkat penyerapan tinggi, dan bergapten di antara mereka memiliki nilai P app tertinggi , menunjukkan 93,49 × 10 −6 cm s −1 .

Studi ini memilih 40 deskriptor molekuler menggunakan PaDEL-Descriptor dan alvaDesc sesuai dengan Acuña-Guzman et al . 18 , dengan beberapa modifikasi (lihat Informasi pendukung, Tabel S3 ). Ke-40 deskriptor molekuler yang diterapkan pada fitokimia diselidiki untuk bioavailabilitas dari SMILES mereka. Di antara mereka, empat fitokimia (punicalagin, thiostrepton, glycyrrhizin dan rebaudioside A) menyebabkan kesalahan dalam perangkat lunak dengan struktur molekuler yang terlalu kompleks dan dikecualikan. Akibatnya, kumpulan data dengan 9840 entri terdiri dari nilai untuk 40 deskriptor molekuler dan tiga pengukuran berulang ΔTEER, P app dan ER dari 80 fitokimia.
Untuk menunjukkan distribusi dataset, studi sebelumnya menggunakan PCA untuk memvisualisasikan partisi dataset pada ruang kimia. 31 Baru-baru ini, PCA digunakan untuk mengonfirmasi distribusi set pelatihan dan pengujian untuk deskriptor molekuler yang diekstraksi. 18 Dalam studi saat ini, dataset dari 40 deskriptor molekuler dianalisis dengan beberapa modifikasi dari studi oleh Acuña-Guzman et al . 18 , yang menunjukkan bahwa 28 komponen utama (PC) pertama menjelaskan 99,18% dari varians kumulatif. Ini menunjukkan bahwa dataset dapat dioptimalkan untuk meningkatkan efisiensi model dan meminimalkan overfitting melalui pengurangan dimensionalitas yang efektif. Lebih jauh, set pengujian dan pengujian dari 40 deskriptor molekuler divisualisasikan pada plot skor PCA, di mana empat PC pertama diplot secara representatif pada Gambar. 4 . Ditemukan bahwa set pelatihan dan pengujian diplot dalam karakteristik yang sama di ruang kimia, menunjukkan bahwa dataset untuk 40 deskriptor molekuler dipartisi dengan tepat.

Pengembangan model QSPR dengan regresor hutan acak
Model QSPR menggunakan regresor hutan acak dikembangkan untuk masing-masing dari tiga indikator bioavailabilitas (ΔTEER, P app dan ER) yang tercantum dalam Tabel 2. Dalam setiap kasus, 40 deskriptor molekuler terpilih digunakan sebagai variabel independen untuk memprediksi variabel dependen. Nilai prediksi dan eksperimen divisualisasikan menggunakan scatter plot, yang memungkinkan perbandingan yang jelas dari kinerja model di semua set pengujian, seperti yang ditunjukkan pada Gambar 5. Dalam kasus ΔTEER, model tersebut bekerja pada set pelatihan dengan menjelaskan 86% varians ( R 2 Train = 0,86) dengan RMSE Train sebesar 55,25, yang menunjukkan bahwa model tersebut secara efektif sesuai dengan data pelatihan. Namun, selama validasi silang (CV), kinerjanya menurun, menunjukkan R 2 CV sebesar 0,43 ± 0,17 dan RMSE CV sebesar 106,25 ± 30,6. Hasilnya menunjukkan bahwa model tersebut mungkin memiliki keterbatasan dalam menggeneralisasi ke yang lebih kompleks atau yang sebelumnya tidak teramati dalam data. Meskipun demikian, kinerja set pengujian meningkat, dengan Uji R 2 sebesar 0,63 dan Uji RMSE sebesar 74,77, yang menunjukkan potensi generalisasi yang lebih baik. Nilai ΔTEER yang diprediksi dan aktual divisualisasikan pada sebaran plot (Gbr. 5A ). Nilai PC adalah 0,824, yang menyiratkan hubungan positif yang kuat antara nilai yang diprediksi dan aktual. Nilai yang diprediksi umumnya mengikuti tren positif relatif terhadap nilai aktual. Namun, ada beberapa penyimpangan dari linearitas sempurna, yang menunjukkan bahwa model menangkap pola keseluruhan, tetapi prediksi tertentu menyimpang dari nilai aktual. Mengenai aplikasi P , model menunjukkan kinerja yang kuat pada set pelatihan, dengan Kereta RMSE sebesar 4,54 × 10 −6 dan Kereta R 2 sebesar 0,95, yang berhasil menjelaskan 95% varians dengan kesalahan minimal. Kinerja validasi silang menunjukkan peningkatan dibandingkan dengan hasil ΔTEER, dengan RMSE CV sebesar 8,82 × 10 −6 ± 8,02 × 10 −7 dan R 2 CV sebesar 0,77 ± 0,09, yang menunjukkan bahwa model menunjukkan kinerja yang lebih baik sehubungan dengan penerapan pada data yang tidak terlihat dibandingkan dengan ΔTEER. Hasil set pengujian ( Uji RMSE = 6,23 × 10 −6 dan Uji R 2 = 0,91) mengungkapkan bahwa model bekerja secara konsisten pada data baru. Model mempertahankan keseimbangan yang baik antara penyesuaian data pelatihan dan generalisasi. Aplikasi P yang diprediksi dan aktualNilai-nilai divisualisasikan pada diagram sebar (Gbr. 5B ). PC sebesar 0,935 menunjukkan korelasi positif yang sangat kuat antara nilai yang diprediksi dan nilai aktual. Prediksi model sangat sesuai dengan nilai aktual, yang menunjukkan kemampuannya untuk menggeneralisasi data yang tidak terlihat dengan baik. Meskipun terdapat sedikit perbedaan, model secara keseluruhan menunjukkan efektivitas dalam memprediksi indikator aplikasi P , yang mencapai keseimbangan yang baik antara akurasi dan kesalahan yang rendah.
| Indikator bioavailabilitas | Kereta RMSE | Kereta R 2 | Riwayat Hidup RMSE | R 2 CV | Tes RMSE | Uji R 2 |
|---|---|---|---|---|---|---|
| TEHERAN | 55.25 | 0.856 | 106,25 ± 30,6 | 0,43 ± 0,17 | 74.76 | 0.63 |
| Papp | 4,57 × 10−6 | 0,95 | 8,82 × 10−6 ± 8,02 × 10−7 | 0,77 ± 0,09 | 6,23 × 10−6 | 0,91 |
| Rasio efluks | 0.39 | 0.92 | 0,68 ± 0,15 | 0,71 ± 0,10 | 0.71 | 0,85 |

Untuk ER, model menunjukkan kinerja yang kuat pada set pelatihan, dengan RMSE Train sebesar 0,39 dan R 2 Train sebesar 0,92, menjelaskan 92% varians dengan kesalahan yang relatif rendah, mengonfirmasi kecocokan yang hebat dengan data pelatihan. Hasil validasi silang menunjukkan sedikit penurunan dengan R 2 CV sebesar 0,71 ± 0,10 dan RMSE CV sebesar 0,68 ± 0,15, yang menunjukkan bahwa model dapat menggeneralisasi data baru meskipun ada penurunan kinerja yang moderat. Pada set pengujian, model mencapai R 2 Test sebesar 0,85 dan RMSE Test sebesar 0,71, yang menunjukkan generalisasi yang andal dengan overfitting minimal. Konsistensi antara hasil validasi silang dan pengujian menunjukkan bahwa model tersebut adalah prediktor ER yang kuat. Plot sebar dari rasio efluks dihasilkan untuk membandingkan nilai prediksi dan aktual (Gbr. 5C ). PC sebesar 0,904 menunjukkan hubungan positif yang kuat antara nilai prediksi dan aktual. Meskipun prediksi secara umum sesuai dengan data aktual, beberapa penyimpangan kecil terlihat. Meskipun demikian, model tersebut menunjukkan kemampuan prediksi yang kuat, dan kinerjanya menunjukkan bahwa model tersebut menangani indikator ini secara efektif, dengan potensi untuk perbaikan lebih lanjut.
Di ketiga indikator bioavailabilitas, model QSPR dengan regresor hutan acak bekerja secara efektif pada data pelatihan, menjelaskan sebagian besar varians. Meskipun hasil validasi silang mengungkap beberapa tantangan dalam generalisasi, terutama dengan pola yang lebih kompleks, kinerja set pengujian menunjukkan kemampuan model untuk melakukan generalisasi dengan overfitting minimal.
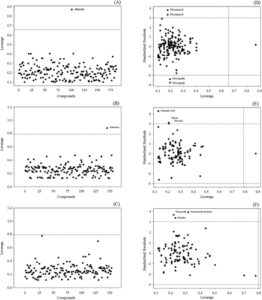
AD untuk evaluasi pelengkap keandalan model
AD mengidentifikasi keandalan data indikator bioavailabilitas (ΔTEER, P app dan ER) untuk mengembangkan model QSPR, yang selaras dengan pedoman ketiga dalam prinsip-prinsip OECD. 20 Ditemukan bahwa AD yang menggunakan leverage dan plot Williams memungkinkan validasi kinerja model, mengidentifikasi titik-titik leverage tinggi dan outlier yang dapat memengaruhi keandalan dan prediksi model. 32 Dalam penelitian saat ini, AD yang tidak dapat digunakan oleh regresor hutan acak digunakan untuk evaluasi komplementer. Dengan kata lain, regresi linier diterapkan untuk menghitung nilai leverage dan menentukan rentang penerapan. Evaluasi komplementer melalui AD ini membantu mengonfirmasi validitas kumpulan data untuk pemodelan QSPR. Dalam Gambar 6(A–C) , plot leverage menunjukkan nilai leverage untuk indikator bioavailabilitas dalam kumpulan data, yang memberikan wawasan tentang keandalan model. Plot menyoroti titik-titik data dengan nilai leverage tinggi yang melampaui ambang batas leverage peringatan ( h *), yang menunjukkan potensi pengaruh yang tidak semestinya dari titik-titik ini pada model. Nilai h * untuk ΔTEER, P app dan ER masing-masing adalah 0,6578, 0,7885 dan 0,7987. Misalnya, allantoin dalam kasus dataset ΔTEER dan P app melebihi nilai h * (Gbr. 6A, B ). Sebaliknya, tidak ada fitokimia yang melebihi nilai h * masing-masing dalam rasio efluks (Gbr. 6C ). Studi saat ini juga melakukan plot Williams, yang menggabungkan leverage dengan residual terstandarisasi untuk mengidentifikasi outlier (Gbr. 6D–F ). Titik data dengan residual lebih besar dari ±3 dievaluasi sebagai outlier, yang memungkinkan penilaian lebih lanjut tentang keandalan model. Dalam dataset ΔTEER, dicoumarol dan hecogenin diidentifikasi sebagai outlier (Gbr. 6D ). Untuk kumpulan data aplikasi P , asam sinamat, salisin, dan diosmin dikenali sebagai outlier, sedangkan hematoksilin hidrat, hesperetin, dan betulin ditandai dalam kumpulan data rasio efluks (Gbr. 6E,F ). Hasil dari studi terkini menunjukkan bahwa evaluasi pelengkap dari kumpulan data dan model dapat meningkatkan pengembangan model yang lebih tangguh dan andal dengan mengidentifikasi dan menghilangkan outlier. Investigasi lebih lanjut mengenai dampak titik leverage tinggi dan outlier, dikombinasikan dengan pemilihan fitur yang lebih baik dan penyetelan model, diperlukan untuk meningkatkan akurasi prediktif dan generalisasi model untuk prediksi bioavailabilitas.
Secara keseluruhan, penelitian ini mengukur indikator bioavailabilitas seperti ΔTEER, P app dan ER untuk 84 fitokimia menggunakan uji sel Caco-2, diikuti oleh pengembangan model QSPR menggunakan regresor hutan acak untuk memprediksi bioavailabilitas senyawa-senyawa ini. Model ini menunjukkan kinerja yang kuat pada data pelatihan, yang secara efektif menjelaskan sebagian besar varians. Namun, validasi silang mengungkapkan beberapa keterbatasan dalam generalisasi, khususnya untuk senyawa yang kompleks secara struktural atau baru, yang menunjukkan perlunya penyempurnaan lebih lanjut. Kinerja model kami dinilai menggunakan metrik evaluasi yang terstandarisasi dan objektif, termasuk R 2 , RMSE dan AD ( nilai h *). Dalam penelitian sebelumnya, R 2 dan RMSE telah banyak digunakan untuk menilai akurasi model; misalnya, model QSPR ensemble mencapai R 2 = 0,76 dan RMSE = 0,38, pada saat yang sama mempertahankan keandalan prediksi melalui evaluasi AD menggunakan ambang batas leverage peringatan ( h * = 0,0866) [18]. Demikian pula, studi QSPR lain pada pelarutan nanopartikel berbasis logam melaporkan nilai R2 lebih besar dari 0,7 sebagai indikasi kinerja prediktif yang memadai. 33 Metrik ini umumnya diadopsi dalam penelitian QSPR dan mendukung validitas dan komparabilitas pendekatan pemodelan kami. Dibandingkan dengan karya-karya sebelumnya seperti yang dilakukan oleh Hou et al ., 34 yang berfokus pada prediksi aplikasi P menggunakan regresi linier dengan deskriptor molekuler seperti logD dan luas permukaan polar ( r2 = 0,82 pada set senyawa kecil) dan yang dilakukan oleh Wang et al ., 35 yang menggunakan jaringan saraf RBF ganda yang mencapai R2 = 0,77 pada set data yang lebih besar dari 1827 senyawa, studi kami memperluas cakupan prediktif dengan memodelkan tiga indikator bioavailabilitas utama secara bersamaan. Selain itu, model kami menggabungkan fitokimia alami yang beragam secara struktural, yang sering kali kurang terwakili dalam set data QSPR. Yang penting, penggunaan analisis AD dan penghapusan outlier meningkatkan keandalan model, yang merupakan aspek yang belum banyak dibahas dalam banyak model sebelumnya.
Evaluasi pelengkap pemodelan QSPR ini menyoroti pentingnya menangani outlier untuk meningkatkan generalisasi model. Studi mendatang harus bertujuan untuk menggabungkan data yang lebih beragam secara struktural, menyempurnakan teknik AD, dan mengeksplorasi pendekatan pembelajaran mesin tingkat lanjut seperti jaringan saraf dalam (DNN) untuk menangkap potensi korelasi non-linier di antara ΔTEER, P app , dan ER. Secara keseluruhan, temuan kami memperluas penerapan pemodelan QSPR ke ranah fitokimia fungsional, yang berkontribusi pada penemuan bahan bioaktif baru. Selain itu, studi ini mengeksplorasi potensi untuk mengembangkan model prediktif berdasarkan indikator bioavailabilitas yang ditentukan secara eksperimental melalui pengujian in vitro kami sendiri . Meskipun banyak penelitian sebelumnya telah menggunakan model QSPR untuk memperkirakan sifat terkait penyerapan, sejauh pengetahuan kami, tidak ada yang membangun model menggunakan parameter bioavailabilitas yang diukur secara langsung, khususnya ΔTEER, P app , dan ER, yang diperoleh dari pengujian Caco-2 eksperimental. Hal ini menyoroti kebaruan dan orisinalitas pendekatan kami dalam mengintegrasikan data empiris dengan pemodelan komputasional.
KESIMPULAN
Dalam penelitian saat ini, indikator bioavailabilitas (ΔTEER, P app dan ER) untuk 84 fitokimia diukur menggunakan sel Caco-2, dan kemudian model QSPR menggunakan regresor hutan acak digunakan untuk memprediksi bioavailabilitas 84 fitokimia.
Model tersebut menunjukkan kinerja yang kuat pada data pelatihan, yang secara efektif menjelaskan sebagian besar varians. Namun, hasil validasi silang mengungkapkan beberapa tantangan dalam generalisasi, khususnya untuk pola yang lebih kompleks atau yang sebelumnya tidak teramati, yang menunjukkan perlunya penyempurnaan lebih lanjut. Analisis AD memungkinkan identifikasi outlier dan titik leverage tinggi, dan penghapusan outlier ini menunjukkan potensi untuk mengurangi variabilitas model dan meningkatkan keandalan. Evaluasi pelengkap pemodelan QSPR ini menyoroti pentingnya menangani outlier dalam proses pengembangan model untuk meningkatkan akurasi dan generalisasi. Studi mendatang harus fokus pada peningkatan generalisasi model, khususnya dengan menggabungkan kumpulan data yang lebih beragam dan kompleks, serta menyempurnakan identifikasi dan penanganan outlier untuk memaksimalkan akurasi prediktif. Selain itu, pengembangan teknik pembelajaran mendalam, seperti DNN, dapat dieksplorasi untuk mengungkap korelasi potensial antara tiga indikator bioavailabilitas. Hasil dari studi saat ini menunjukkan bahwa penerapan pemodelan QSPR untuk memprediksi bioavailabilitas fitokimia dapat berkontribusi pada kemajuan dalam penemuan bahan fungsional.


